OneDrive にファイルを置くと正しく動かなくなる問題
「あ…ありのまま 今 起こったことを話すぜ!」(・・・以下略)
ExcelファイルをOneDrive上のディレクトリ内に置くとマクロ実行で以下のエラー(8007007B)が出るようになりました。
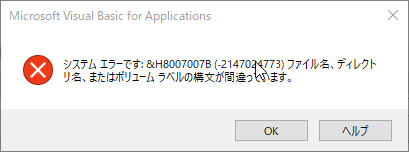
このエラーはある1名のスタッフのみで発生していて最初はどういう条件で起きるのかさっぱり分かりませんでした。 後からそのスタッフだけExcelファイルをOneDrive上に置いていることがわかり、エラーの特定になりましたが、 ほんと、何でそんな事でエラーが起きるのか・・・。
調べてみると VBAマクロの以下の部分に問題がありました。
' カレントディレクトリを実行ファイルのあるパスにする
CreateObject("WScript.Shell").CurrentDirectory = ThisWorkbook.Path
ThisWorkbook.Pathの値が通常は置かれているファイルパスになりますが、ExcelファイルをOneDrive上に置くと、https://d.docs.live.net/〇〇〇〇〇〇 とOneDriveサーバー上のURLを指している為に上記のエラーが出ていました。実際にファイルの置かれていいるローカルPC上のパス情報は ThisWorkbook からは取れません・・・・。
そもそも OneDriveサーバー上のファイルからはマクロが動かない癖に、 何でそんな仕様になっているんだよ!
取りあえず httpを判定して回避
If Left(ThisWorkbook.Path, 4) <> "http" Then CreateObject("WScript.Shell").CurrentDirectory = ThisWorkbook.Path
Excelの勤務時間計算で24時間が消える問題
「あ…ありのまま 今 起こったことを話すぜ!」
「出勤時間を計算して合計144時間になったが、セルの値をコピーしたら120時間になっていたんだ」
「な… 何を言っているのか わからねーと思うが、おれも何をされたのかわからなかった… 頭がどうにかなりそうだった…」
「浮動小数点の誤差とかそんなチャチなもんじゃあ 断じてねえ… もっと恐ろしいものの片鱗を味わったぜ…」
…つまりですね、弊社ではスタッフの勤務時間の計算をエクセルで行っていたのですが何故か計算結果が24時間分減っている事例が起きていました。 で、原因は良くある「浮動小数点の誤差」が関連するのですが それでも24時間分が無くなる仕組みが 明確にわかっていなかったので、 その原因を今回詳細に調べました。
エクセル内部の仕組み
知っている人も多いと思いますが、Excelの日付時間はシリアル値で保存されています。 シリアル値は整数部が1900年01月01日を1を起点とした日付、少数部が1.0を24時間とした数値で時間を表しています。 デバッガで確認するとセル内部の型としては Variant/Double が使用されています。
これをエクセルで表示すると以下のように表示されます。

問題となる例
問題は勤務時間の総計セルを別のセルにコピーした際に起きていました。
同じ状態を再現するために総計したA1セルをVBAで別のセルにコピーしてそれぞれの書式で表示しています。
- プログラム
Sub CopyCell()
formats = Array("[h]:mm", "yyyy/mm/dd hh:mm:ss", "0.000000000000000000")
With ThisWorkbook.ActiveSheet
Dim sumDate As Date
Dim sumDble As Double
Dim sumVari As Variant
sumDate = .Range("A1").Value
sumDble = .Range("A1").Value
sumVari = .Range("A1").Value
For i = LBound(formats) To UBound(formats)
.Range(.Cells(2, i + 4), .Cells(5, i + 4)).NumberFormatLocal = formats(i)
.Cells(2, i + 4).Value = sumDate
.Cells(3, i + 4).Value = sumDble
.Cells(4, i + 4).Value = sumVari
.Cells(5, i + 4).Value = .Range("A1").Value
Next
End With
End Sub
- 参照元

- 結果

見てわかる通り、セルの値を一旦Date型にコピーすると24時間分減っています。今回はこのパターンで発生していました。
一見、型を変えてやれば上手くいくように見えて実はそうではありません。
見た目上、正しく表示されているDouble型の時間のセルをダブルクリックすると日付表示になりますが
この値は「1900/1/5 00:00:00」と表示され、日付の値と一致しません。

この状態でセルを移動させると値が変化します。

「なんじゃそりゃーーーーーーーーーー!!」
原因を探る
勤務時間を計算する場合は「時間」で計算するのですが、「時間」はシリアル値の少数部であるため計算上の誤差が生じます。 ただ本来この誤差は無視できるほどの小さいので(あっても±1秒差が起きる程度)問題が起きるような事は本来考えにくいのですが、 型変換をした際の誤差が何かしらの影響を及ぼしていたと考えていました。
しかし、24時間の変化はそれだけでは説明がつきません。
まずは誤差がどの程度あったかを調べます。
しかし誤差は小さすぎるためにセルの書式設定で小数点をいくら表示しても現れませんし、VBAデバッガでも表示されませんでした。
少数部のみを取得するプログラムを挿入して確認した所、少数部は0.999999999999998であることがわかりました。

つまり 144時間 -> 120時間になる数値は 5.999999999999998 という事になります。
次に現象が起きる誤差範囲を調べたところ、少数部が1 - (1/ (24 * 60 * 60 * 2))の境界で起きる事がわかりました。
 つまり、少数部を四捨五入して数値化する際に23:59:59を超えて00:00:00になる場合にこの現象が発生します。
つまり、少数部を四捨五入して数値化する際に23:59:59を超えて00:00:00になる場合にこの現象が発生します。
結論
どうやら「シリアル値を日付文字列にするアルゴリズムが間違っている」様です。 文字列を生成する際に整数部(日付)と少数部(時間)を分けて計算しているようで、 少数部(時間)が23時間59分59秒を超えた場合に時間は00:00:00になりますが、 その際に整数部(日付)への繰り上がりが必要なのにこれを行っていない為に1日のずれが起きています。
つまり、この文字列変換を通す場合に1日のずれが発生します。
- 該当セルをクリックして式を見ると文字列変換された日付表示が表示されます。この値は正しくありません。
- ダブルクリック後すると、文字列変換された日付表示がセル上に表示されます。この値は正しくありません。
- ダブルクリック後にカーソルを動かすと、その日付表示で再入力されるために数値が書き換わります。
- ダブルクリック後に[Esc]キーで抜けた場合は、再入力されないため変化が起きません。
- Double -> Date 型に変換の場合に値が変化する理由は、Double -> 文字列変換 -> Date値という手順で変換している為と思われます。
対処法
対処法としてはシリアル値自体を文字列変換が起きても正しい値が表示される補正をする事です。 具体的には秒数側が 23:59:59.5 を超えた場合に秒数を0にして整数値に繰り上げさせます。
シリアル値を下記の関数に通すことで問題は発生しなくなることを確認しました。
Function RoundSec(d As Double) As Double
RoundSec = Round(d * 86400#) / 86400# ' 86400 = 24 * 60 * 60
End Function
検証環境
Microsoft Windows 10 Pro for Workstations 10.0.19045 ビルド 19045 Microsoft® Excel® for Microsoft 365 MSO (バージョン 2302 ビルド 16.0.16130.20186) 64 ビット
テスト用エクセル https://1drv.ms/u/s!Aj1C4e43DYFurFZtVvMuGmHvY905?e=OI17yt
C++:関数の返り値の書き方
前回の引数の渡し方に続いて、今度は返り値の渡し方について説明します。
返り値も考え方は引数と大きく変わりません。メモリのコピーを抑えるために、
- 基本型は「値渡し」
- 基本型以外は「参照渡し」
で渡したいと考えます。しかし、返り値の場合は「参照渡し」では問題になります。次の例を見てみましょう。
Add()関数にて Vector2型を「参照渡し」していますが、returnする result は関数内で確保された変数なので、関数を抜けると破棄されます。この場合、返り値は不明な値となります。つまり、返り値では引数の様に参照渡しが出来ません。
#include <iostream> class Vector2 { public: float x, y; Vector2(float _x, float _y) : x(_x), y(_y) {} }; const Vector2& Add(const Vector2 & val1, const Vector2 & val2 ) { Vector2 result(val1.x + val2.x, val1.y + val2.y); return result; //<- 関数を抜けると破棄される。 } void main() { Vector2 v1( 1, 2 ); Vector2 v2( 3, 4 ); const Vector2& v3 = Add(v1, v2); };
ただし、参照渡しできる条件があります。次の例では Add()関数を Vector2 クラス内に入れ、自分自身と加算する形に変更しました。返り値はオブジェクト自身を返していますので関数を抜けても無くなりません。
#include <iostream> class Vector2 { public: float x, y; Vector2(float _x, float _y) : x(_x), y(_y) {} const Vector2& Add(const Vector2& val ) { x += val.x; y += val.y; return *this; // <- 自分自身の内容を渡す。 } }; void main() { Vector2 v1( 1, 2 ); Vector2 v2( 3, 4 ); const Vector2& v3 = v1.Add(v2); // v1の中身を参照型として渡す。 std::cout << "v1 = " << v1.x << ", " << v1.y << std::endl; std::cout << "v3 = " << v3.x << ", " << v3.y << std::endl; };
結果は以下の通り。v3 は v1 の参照を返しているので、v1 と v3 は同じ結果になります。
v1 = 4, 6 v3 = 4, 6
返り値にconst をつけるか否かは、渡したオブジェクトをその後書き換えて良いかどうかで決めます。オブジェクト本体を返す場合は付けない方が良いでしょう。オブジェクトが持つ「メンバ変数」を返す場合は、オブジェクトを介さずに書き換えられないように、なるべく const を付けてください。
上記の例では、v1 オブジェクト本体を返していますので const をつけていません。そうすることで以下の様に連続してメソッドを呼び出すことができます。
const Vector2& v3 = v1.Add(v2).Add(v2).Add(v2); // v1に対して3回v2をAddする
まとめると、返り値の渡し方は2つ
- 「クラスの本体、もしくはメンバの返す関数」で、「基本型以外」の場合は参照渡し。
- 「それ以外」は値渡し
// 「クラスの本体、もしくはメンバの返す関数」で、「基本型以外」 Typename& func(); // 返り値を書き換えても良い場合。主にオブジェクト本体を返す const Typename& func(); // 返り値を書き換えてほしくない場合。主にメンバ変数を返す // 「それ以外」 Typename func();
返り値の負荷を抑える方法
そうなると、基本型以外で値渡しを返す場合があるので負荷が高くなるのでは?という疑問がわくと思いますが、 「まさにその通り」 です。C++では言語仕様上、どうしても返り値で負荷がかかりやすい設計になっています。
回避する方法はいくつかあります。
1つは「引数」をつかって値を返す方法。引数の時に説明しましたが、const 無しの参照型の引数をもらい、そこに返す値を入れます。コピーが行われないので負荷がかかりません。
void func(Typename & out_result);
この方法は見た目に直感的な書き方にはならないので嫌う方もいますが、動作としては分かりやすい事と、最も速い返し方になるので初心者の方にはお勧めです。
// 引数で値をもらう。 Object out_result; FindObject(out_result); // 返り値で値をもらう。こちらの方がより直感的に書ける。 Object result = FindObject();
そしてもう一つは、C++11で導入された「ムーブコンストラクタ」です。これは返り値を渡す際の無駄なコピーを防ぐために作られたといっても過言ではありません。通常クラスを値渡しする際には「コピーコンストラクタ」が呼び出されますが、元を破棄してよい条件に限り「コピーコンストラクタ」では無く「ムーブコンストラクタ」が呼び出されるというものです。
「ムーブコンストラクタ」が使われる条件がいくつかありますが、内部動作を理解していないと判断が難しいため、ムーブコンストラクタを使って負荷を下げているつもりが、実は使われていないという事もありうるので注意しましょう。初心者の内は使わずに、引数で渡す方法の方が良いと思います。
それでも使いたい人は以下を読んでください。
ムーブコンストラクタ
詳しくは 右辺値参照・ムーブセマンティクス - cpprefjp C++日本語リファレンス を見てもらうと良いですが、ムーブコンストラクタについて動作原理を簡単に説明します。下記の図を見てください。

2つの違いはクラス内部のポインタの先を使いまわすか、しないかの差です。ムーブコンストラクタでは「元の変数を破棄してよい」という条件が満たされた場合にのみ呼び出されます。ポインタで保持しているオブジェクト本体をコピー(ディープコピー)せずにポインタをコピー(シャローコピー)するだけにします。つまりクラス内部のデータの殆どがポインタ管理されている場合にしか効果がありません。
そして「元を破棄してよい」という条件は、C++の言語仕様上では右辺値と呼ばれますが実際にはかなり細かい区分があるので、正確に理解するのは難しい仕様になっています。一応簡単に言うと「名前のないオブジェクト」の事になります。
Vector2 v1(4, 10); Vector2 v2 = v1; // v1 は名前付きオブジェクトなので、右辺値ではない。 Vector2 v3 = Vector2(4, 10); // Vector2(4, 10) は名前がないオブジェクトなので、右辺値。
まとめるとムーブコンストラクタを使うに値する条件は次の通りになります。これらの判断ができる様であれば使いましょう。
- 元を破棄してよい変数であること。 (名前のないオブジェクト)
- ムーブコンストラクタを定義している。(コピーコンストラクタと違い、自動的にデフォルトのムーブコンストラクタは作られない為)
- クラスがポインタを持ち、クラスが保持しているデータの殆どがポインタ先にある事。
なかなか厳しい条件に見えますが、実は標準ライブラリの文字列やコンテナクラス(std::string, std::vector, std::map)はこれらの条件を満たしていますので、これらを使う場合はムーブコンストラクタで良いでしょう。
ムーブコンストラクタで値を返す方法の例です。
std::string CombineString(const std::string& str1, const std::string& str2) { std::string str12 = str1; str12.append(" + "); str12.append(str2); return std::move(str12); }
return 時に std::move()という関数を使用しています。この関数は変数を右辺値として扱いムーブコンストラクタで渡せるようにする関数です。str12 は名前付きのオブジェクトなので右辺値ではありません。返り値に使用してもムーブコンストラクタにはなりませんが、std::move()を使う事でムーブコンストラクタで渡すことができます。標準ライブラリの文字列や、コンテナクラスはこの様な使い方で返り値を渡しましょう。
C++:関数の引数の書き方
多くの学生作品を見ていると、C++関数の引数の渡し方を正しく書いている人が殆どいません。多くの人が、この辺りを割とうろ覚えのままで書いている印象です。私が作品講評とかする時に必ず指摘する箇所の1つで、社員応募作品のチェック時にはC++を理解しているかどうかの指針として見ている、とても重要なポイントです。
何故重要かというと、C++ではこの部分を間違った書き方をしていると非常に重い処理になってしまう事が多々あるからです。
まずはおさらい
C++関数の引数の渡し方は3つあります。
- 値渡し
- 参照渡し
- ポインタ渡し
値渡し
- C++は引数を渡す場合、通常この「値渡し」を行います
- 「値渡し」は呼び出し元の変数の内容をコピーして渡します
- なので、関数内で引数の内容を変更しても、呼び出し元の変数は変更されません
- コピーなので、変数の使用しているメモリ領域が大きいと、その分のメモリコピーが行われます
ポインタ渡し
- 「ポインタ渡し」は呼び出し元の変数が入っているメモリ領域の先頭アドレス(ポインタ)をコピーして渡します
- なので、関数内でポインタが指す変数の内容を変更すると、呼び出し元の変数も変更されます
- 変数の使用しているメモリ領域が大きくても、ポインタを渡すだけなので高速です
参照渡し
- 「参照渡し」は「ポインタ渡し」と同様に呼び出し元の変数が入っているメモリ領域の先頭アドレスを渡します
- なので、関数内で引数(参照)の内容を変更すると、呼び出し元の変数も変更されます
- アセンブラレベルでの動作は「ポインタ渡し」と同じですが、渡されるのがポインタ型ではなく参照型である為、「ポインタ型」にある+, ++, -, -- 等の演算子でアドレスを操作できません。ポインタでは可能だった変数メモリ領域外のアクセスを防ぐことができるため、C++では基本的に「ポインタ渡し」代わりに「参照渡し」をします
同じ int を掛け算する関数を、それぞれの渡し方で書いてみると以下のようになります。
int mult_call_by_value (int x, int y) { return x * y ; } int mult_call_by_pointer (int* x, int* y) { return (*x) * (*y); } int mult_call_by_reference(int& x, int& y) { return x * y ; } void main() { int a = 10, b= 5; int r1 = mult_call_by_value(a,b); int r2 = mult_call_by_pointer(&a,&b); int r3 = mult_call_by_reference(a,b); }
使い分け
さて、ここまでは理解している人は多いと思います。困ったことに、どれを使ってもC++文法上では間違いではありません。しかし、書き方次第で負荷が大きく変わってきます。「どういう場合に使うのか?」「どういう書き方にすべきなのか?」というのはC++の動作の仕組みを理解していると、ルールがおのずと見えてきます。
まず、基本型がそれ以外で書き方を分けます。ここでいう基本型とは void 型を除いた int, bool, char, short, long, float double, wchar_t とそれをtypedef したものです。基本型というのはCPUが直接扱える型でありメモリへのコピーは1回で済みます。基本型以外の型(クラス、構造体、配列)は多くのメモリ領域を使用していることが多く、場合によっては 数100~数1000byteのメモリを使用しています。関数を呼び出すたびに大量のメモリのコピーが行われるので非常に重くなります。
その為、基本型以外の変数は必ず「参照渡し」にしてください。そして参照渡しては元の値が書き換えられてしまう可能性があるので、それを禁止する為に const をつけます。
- 基本型以外(クラス、構造体、配列)はconst付きの参照渡し
void func( const Typename& arg ); // 基本型以外
逆に、基本型は値1つのみの最小限のメモリコピーになります。呼び出し規約によってはメモリを介さずにCPUのレジスタでやり取りするので、非常に高速に渡せます。その為、必ず値渡しにします。元の値を書き換えることが出来ないので const をつける必要がありません。
- 基本型は値渡し
void func( Typename arg ); // 基本型
関数から値を受け取る場合は、型には関係なく以下の書き方になります。この場合、引数名に "out_~"をつけるようにすると区別がつけやすいです。(ここら辺は各社さんのコーディングルールによりますが)
- const 無しの参照渡し
void func( Typename& out_arg ); // 引数で返り値をもらう場合
さて、最後にポインタ渡しについてです。
ポインタ渡しは参照型で書けるので参照渡しで書くのが基本ですが、そもそも new でオブジェクトを生成した時の型はポインタ型になるので、ポインタ渡しを完全に排除することはできません。現場でも以外に多く使われています。以下の例の様にオブジェクトを受け渡したり、他で保持する為に渡す場合はポインタ型で扱う事になります。
- new で生成したオブジェクトを他のクラス(例えばマネージャークラスや親クラス)で保持する為にポインタを渡す
- キャッシュとしてコピーしてメンバとして保持する場合
const を付けるか付けないかに関しては、ポインタを保持する側で変更処理をさせるか、させないかで、付ける、付けないが変わります。
void func( const Typename* arg ); // ポインタを保持する側が変更できない想定で、渡す。 void func( Typename* arg ); // ポインタを保持する側が変更できる想定で、渡す。
補足
呼び出し規約について
いずれブログで取り上げますが、呼び出し規約を簡単に説明します。
呼び出し規約とは、関数が呼び出される時に引数と返り値をどの様に受け渡すかのルールを定めたものです。スタックに何を積むか、レジスタは何を指しているか、関数内でどのレジスタを保存するか、等を取り決めています。当然ながら呼び出し側と呼び出される側が同じ呼び出し規約でないと、引数や返り値が正しく受け渡しができないので、リンク時にエラーが起こります。
呼び出し規約によっては、通常はスタックに積む引数をレジスタで渡すようにもできるので、指定の仕方でより高速に関数呼び出しが可能になります。
参照渡しの例外
CEDEC 2016 の スクウェア・エニックスさんの最適化に関する講演にて、Vector型を参照渡ししない方が高速になる、という例が載っています。 http://cedil.cesa.or.jp/cedil_sessions/view/1536
ただ、書類だけだとわかりにくいですが、SIMDを使用した組み込み関数の例で紹介しているので、以下の様に Vector型は __m128型で定義されているものと想定できます。__m128 はC++の基本型ではないですが、コンパイラの拡張機能として、CPUが扱えるレジスタとして1回のコピーで処理できるため値渡しの方が高速になる、という事例です。
class Vector { private: __m128 xmm; public: Vector () {}; // : };
参照渡しにするのはメモリのコピー量が問題になるので、基本型以外でもコピーするメモリ容量が少なければ処理負荷がそこまで高くはなりません。ただクラス等は修正を重ねるうちに肥大化することも多いので、やはり参照渡しにしておくべきと考えます。数が限定的で、なおかつ今後増えない、といった場合には例外的に「値渡し」でも良いでしょう。例えば基本型のペア型(std::pair<>)、基本型3~4つのタプル型(std::tuple<>)位までは許容範囲と考えます。